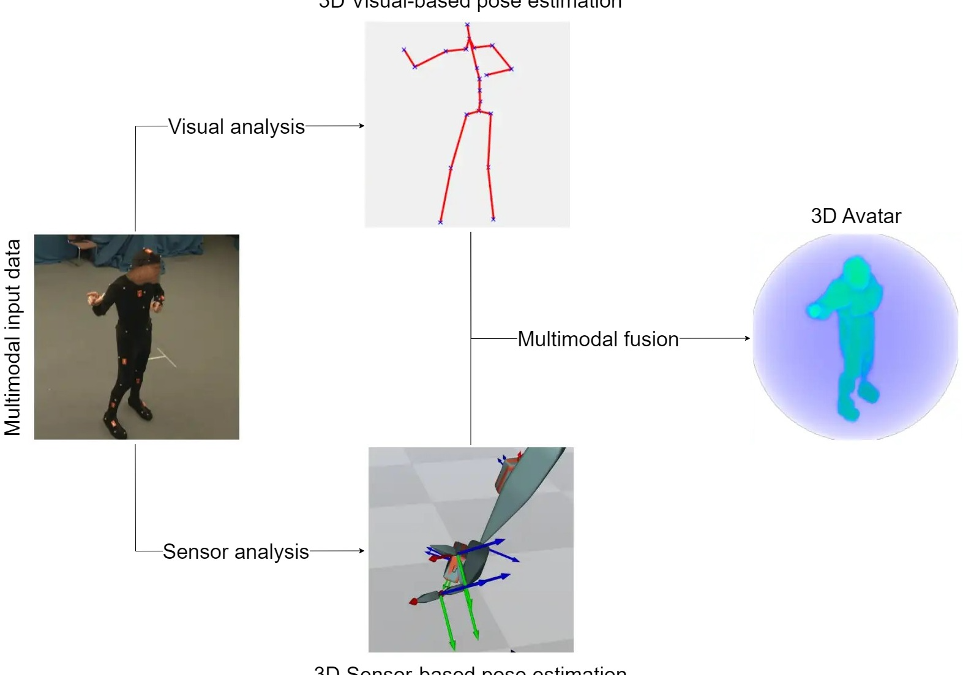
When more than one modality (sensors, cameras, etc.) are deployed to a system for the same reason, it is essential to find robust and efficient ways to combine their data to improve the system’s performance. This is the role of multimodal fusion, a task researched by CERTH. By using multimodal fusion techniques, the system can take advantage of the unique characteristics of each modality, thus making it a robust and accurate system. In general, there are two main directions for multimodal fusion; performing fusion after the individual models of each modality perform each own prediction and fusing data before a unified model performs the final prediction. Some applications that can benefit from multimodal fusion are emotion recognition, hand gesture recognition and 3D pose estimation.
Multimodal data fusion